A maioria dos buscadores da web leva em conta, além da interface visível, o código HTML (se valida ou não) e a arquitetura da informação para calcular a relevância dos elementos que compõem as páginas e telas.
Informações nas camadas mais próximas à página principal são consideradas mais importantes do que as localizadas em camadas mais profundas.
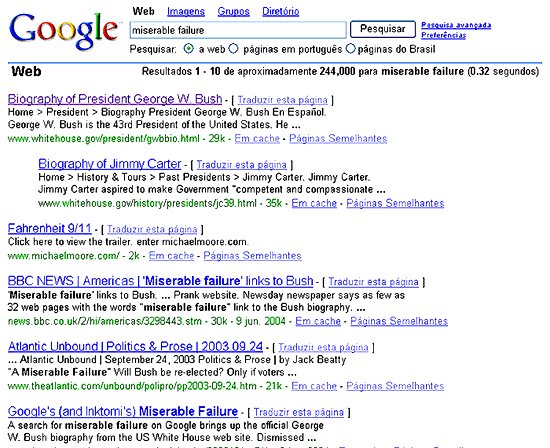
Todas as iniciativas que o governo dos EUA tomou, na época, para neutralizá-la foram inóquas.
O mesmo aconteceu em 2010, também um ano de mobilização eleitorial, com o presidente Lula. Este é um exemplo de como o conteúdo criado pelo usuário pode mobilizar facilmente a opinião pública, através de ações virais em rede.

Uma página não precisa conter uma palavra chave ou expressão para ser associada a ela nas ferramentas de busca, mas a seleção destes termos e expressões pode conduzir milhares de acessos a uma página, especialmente se forem termos e expressões pouco procuradas habitualmente.
Também o número de links que apontam para uma página tem bastante impacto sobre a ordem do link na lista de resultados (especialmente no Google).
Os “blogs” contêm grandes listas que os conectam a outros sites, permitindo boa localização e relevância nos resultados das ferramentas de busca.
Muitos blogueiros utilizam o recursos de divulgar seu trabalho/site para outros procurando causar uma grande incidência de seu nome em outros blogs.
Títulos, links e botões localizados na parte superior da página também sinalizam os assuntos que merecem maior destaque.
Considerar no preparo do código de páginas web para buscas
■ Incluir nos títulos das páginas <title tags> palavras relevantes para as buscas. Os títulos devem ser diferentes para cada página e ter no máximo 70 (incluindo espaços).
Os títulos são tão importantes que o Google se reserva o direito de alterá-los nas páginas de resultados se considerá-los muito longos ou inadequados (como “Untitled”, por exemplo, ou títulos não relacionados ao conteúdo da página). (1)
As palavras mais importantes devem ficar no início, especialmente as que identificam o conteúdo da página. Assuntos devem ser separados por | (pipe). Se o nome da organização não é primordial para a compreensão da página, é recomendável colocá-lo no final do título, ou mesmo não inseri-lo. Não saturar essas marcações com palavras-chave demais, para facilitar a leitura e o arquivamento como favorito nos browsers dos usuários.
É importante também não publicar title tags semelhantes no mesmo site.
■ Posicionar informações consistentes no alto da página (nome do domínio, título dos textos, nome do portal), as primeiras a serem indexadas.
Os títulos de cada texto devem ter explicações sobre o conteúdo – as primeiras posições do título devem conter palavras-chave de maior valor estratégico.
■ Situar o conteúdo mais importante no alto – os 2-3 primeiros Kb de texto de cada página são avaliados com mais rigor que o restante do conteúdo – o cabeçalho da página e as primeiras linhas de texto são especialmente importantes para a indexação. O assunto mais importante de uma página normalmente está localizado (ou sinalizado) na sua área superior. A maioria das ferramentas de busca rastreia apenas 1/3 das páginas e segue para a próxima.
■ Incluir marcações descritivas de imagens (“alt”) e links (“title”), que enriquecem a contextualização do conteúdo.
■ Usar CSS e marcações hierarquizadas de titulação (h1, h2, h3, etc.), que ajudam as “aranhas” dos sites de busca a escalonar o conteúdo mais importante de cada página. Esse fator vem perdendo importância desde 2006.
■ Destacar a importância de textos com estilos bold e itálico.
■ Agrupar JavaScripts no final da página ou em arquivos externos (arquivos com a extensão “.js” – contêm o JavaScript, e apontam para a página HTML que os aplica).
Essa medida evita que muitas linhas de código no topo da página sejam indexadas com maior relevância que o texto dos primeiros parágrafos.
■ No caso das páginas ficarem ligadas entre si via JavaScript (com links não indexáveis), criar uma página com todos os links do site (ou os mais importantes) entre os arquivos do site no servidor.
As meta “robot” dessa página específica devem indicar às ferramentas de busca para seguir os links que contém, mas não indexar a página em si (uso da marcação “no index, follow”).
■ Avisar aos buscadores qual URL de conteúdo duplicado deve ser indexada, publicando, na cabeça (<head>) do código de todas as páginas, a marcação:
<link rel=”canonical” href=”http://www.dominiodo site.com/conteudoPrincipal.htm” />
Dessa maneira, as aranhas identificam o conteúdo da URL canônica identificada como o que deve ser considerado.
■ Validar o HTML e os estilos CSS do site para garantir o acesso universal por diversos browsers, sistemas operacionais e dispositivos. Além disso, erros no código atrapalham o rastreamento pelas ferramentas de busca.
■ Aperfeiçoar sempre o site para que fique cada vez mais amigável para os buscadores.
(Atualizado em 3.5.2017)
Referências
1) Google may change your page titles, Chris Crum (WebProNews, acesso em 13.11.2009)
→ Search Engine Marketing Professional Organization – organização profissional sem fins lucrativos dedicada a promover a conscientização sobre a atividade e o valor das ferramentas de busca
→ Livro: Web marketing – usando ferramentas de busca, de Marcelo Silveira. Editora Novatec
Ferramentas
→ Firebug – extensão para revisão do código HTML, que verifica questões importantes que podem afetar os resultados das buscas
→ Google Page Speed – verifica o tempo de download de uma página. Páginas com alto tempo de carregação podem ser penalizadas pelo Google
→ GTmetrix – compara o tempo de carregação das páginas de diversos sites